构建并结合多个学习器来完成学习任务,我们把它称为模型融合或者集成学习。
不同的模型有各自的长处,具有差异性,而模型融合可以使得发挥出各个模型的优势,让这些相对较弱的模型(学习器)通过某种策略结合起来,达到比较强的模型(学习器)。
在进行模型融合之前,各个基学习器不能够太差,即“准确性”,第二,它们之间要有区分度,即“差异性”。要满足这两点,把多个学习器结合在一起,它们的效果才能比原先的各个基学习器要好。
那么它们都有哪些方法呢?
Blending
Uniform Blending (均匀融合)
Uniform Blending的分类的模型如下,实际上就是少数服从多数的原则,类似于投票:
$$G(\mathbf x)=sign \left( \sum\limits_{t=1}^{T}1 \cdot g_t(\mathbf x)\right)$$
回归模型如下,直接求T个模型g的结果的平均值:
$$G(\mathbf x)= {1\over T}\sum\limits_{t=1}^{T}1 \cdot g_t(\mathbf x)$$
通过Uniform Blending可以减少varience。
分类问题可以想象为投票,回归问题可以想象为加权。
Linear Blending (线性融合)
上面的Uniform Blending,对于每一个模型,无论是回归还是分类,它们的权重是一样的。但是我们稍加改变,为每一个$g$都指定权重。
$$G({\mathbf{x}}) = sign\left( {\sum\limits_{t = 1}^T {{\alpha _t}} \cdot {g_t}({\mathbf{x}})} \right)$$其中,${\alpha _t} \geqslant 0$。那么这些$g$是由最小化评价集合的最小误差得到的,然后通过“特征转化”: $\mathbf z_n = \phi^{-}(\mathbf x_n) = (g_1^{-}(\mathbf x_n), g_2^{-}(\mathbf x_n)...g_{T}^{-}(\mathbf x_n))$,数据变为$(z_n, y_n)$; 而 ${\alpha _t}$通过之前的线性回归,逻辑回归等方法得到投票权重;最后便得到了最终模型。
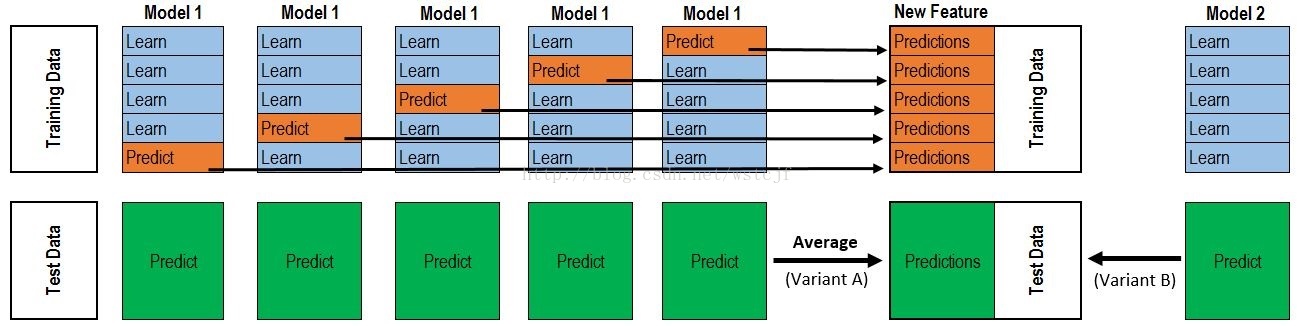
Stacking
Stacking实际上就是把Blending组合起来,Blending只有一层,而Stacking有多层,它把各个基学习器的预测结果作为下一层新的训练集,来学习一个新的学习器。通过元分类器或元回归聚合多个分类或回归模型。基础层次模型(level model)基于完整的训练集进行训练,然后元模型基于基础层次模型的输出进行训练。
总结
上面的这几个方法都是先把小的模型训练出来,然后再进行加权融合。Stacking有个问题,由于它的模型复杂度过高,容易造成过拟合。
在模型融合中,除了不同的算法模型之外,相同的算法模型不同的模型参数,算法中的不同随机种子,也可以用来融合。

参考资料
机器学习技法笔记(9)-Blending and Bagging(模型融合)
机器学习–>集成学习–>Bagging,Boosting,Stacking