前言
做过数据竞赛的同学对XGBoost肯定不会陌生,它在各类竞赛中大放异彩。它比GBDT有着更快的运行速度以及更高的准确率。在许多Kaggle以及天池竞赛中,第一名的队伍都使用了XGBoost。它无论在分类还是回归问题上都有卓越的表现。
我们可能只会用XGBoost,但是对其内部实现确不清楚,为了能够更深入地了解算法细节,本人阅读了作者的论文XGBoost: A Scalable Tree Boosting System ,并参考其他资料,完成本文。
提升树介绍
集合树的计算方法
给定m维的n个数据
树的集成方法使用K个方程来预测输出,也就是把各个树的预测结果累加作为算法的最终结果。
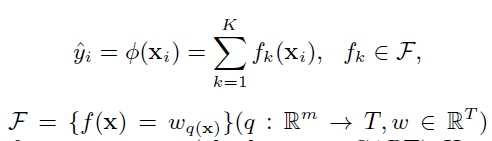
F表示回归树的模型(如:CART),一个回归树对应着输入空间(即特征空间)的一个划分以及在划分单元上输出值。
q表示每一棵树的结构,也就是每一个数据映射到叶子索引上。T是树的叶子数目。每一个$f_k$对应着一棵独立的树
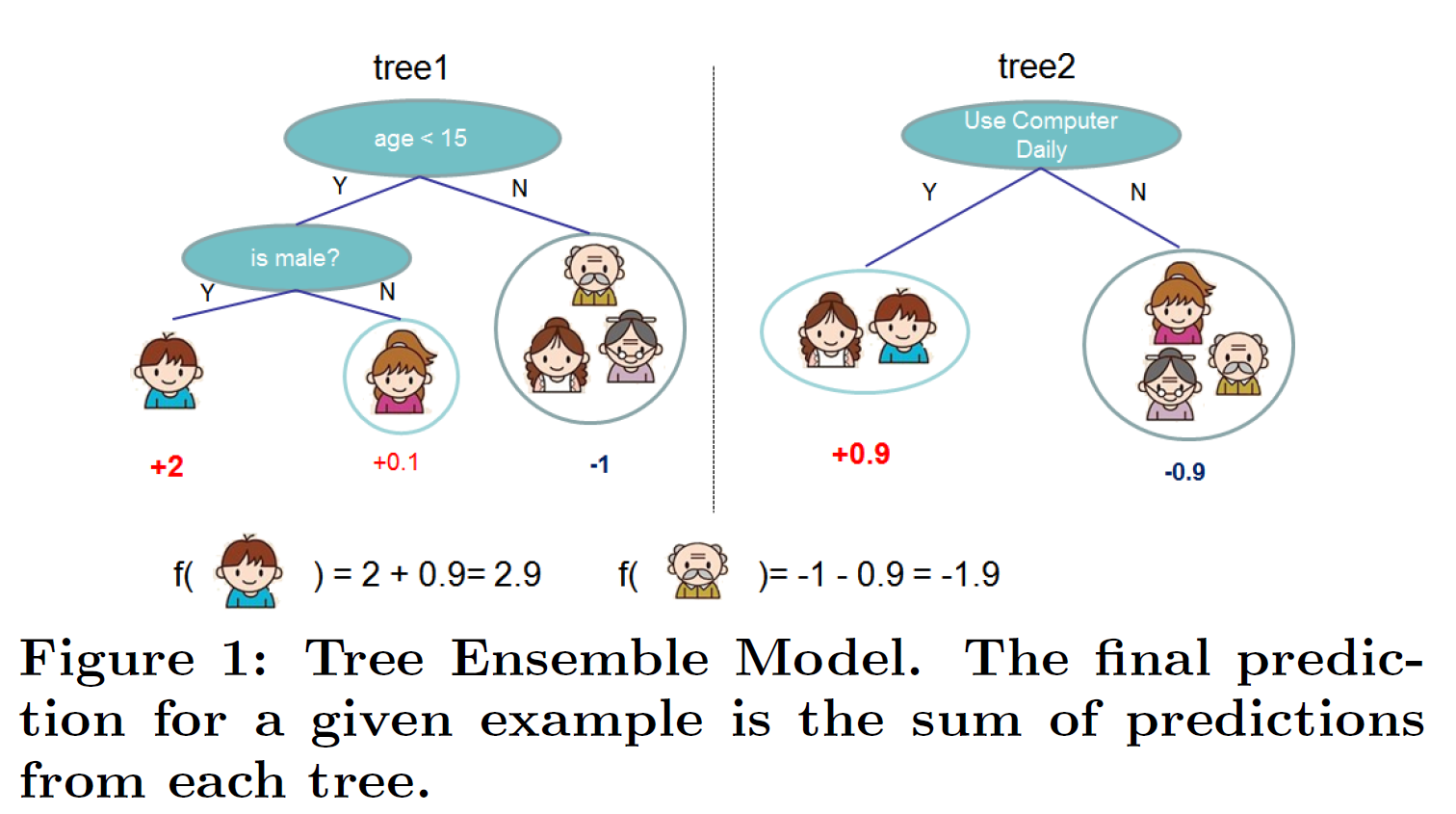
上图展示了树集成模型的计算方法。提升方法实际采用加法模型(即基函数的线性组合)与前向分布算法。以决策树为基函数的提升方法称为提升树(boosting tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉决策树。提升树模型可以表示为决策树的加法模型。
正则化学习目标
为了学习树模型中的参数,构造了如下带有正则化项的目标函数:
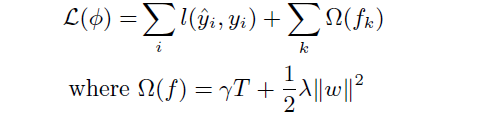
其中l为凸的损失函数,omega为模型复杂度的代价函数,可以减少过拟合的风险。
梯度提升树
提升树采用向前分步算法,首先确定初始提升树${y_0} = 0$,第t步的模型是${y_t} = {y_{t - 1}} + {f_t}({\mathbf{x}})$ 其中,${y_{t - 1}}$为当前模型。
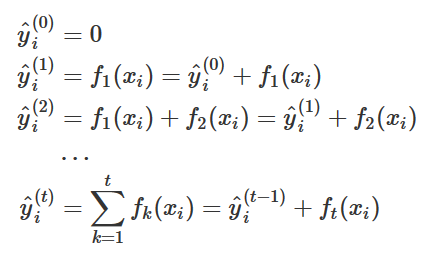
通过经验风险极小化确定下一棵决策树的参数q,构造如下的损失函数:
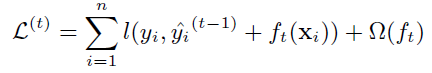
这意味着,我们可以通过不断添加${f_t}$来优化上面的损失函数。二阶相似性可以快速的优化损失函数。
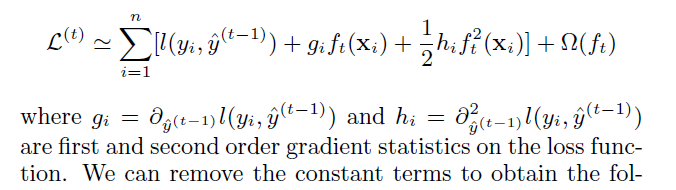
去掉常数项,化简为:
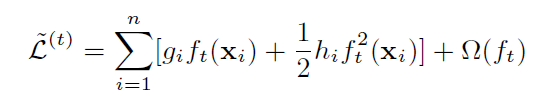
最后,噼里啪啦一顿操作得到红框中的公式:

红框中的式子可以被用来衡量树结构q。
决策树需要找到一个最优的切分变量和切分点,令$I = {I_L} \cup {I_R}$,$I_L$ 和 $I_L$ 为某个实例集合完成切分后的两个节点。那么它的损失减少量可以由下式表示:
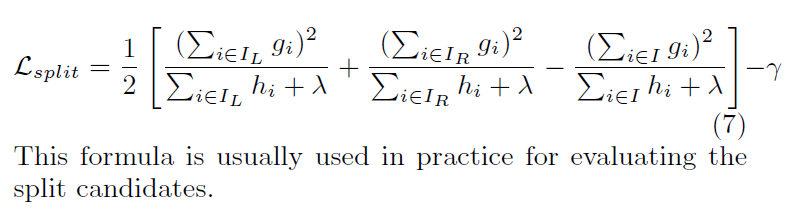
剪枝和列采样
上面的目标函数可以通过添加正则化项来减少过拟合,同样在很多算法中还使用了剪枝和列采样的方式来减少过拟合。
切分点查找算法
传统的精确贪心算法(Basic Exact Greedy Algorithm)
在一般的算法中,如sklearn,以及R语音的gbm,以及简单版本的xgboost都使用这一方法。它需要贪心地去遍历每一个可能的切分点,然后通过 式(7) 来找到最优的切分点。为了提高效率,算法必须先对特征的值进行一个排序,然后遍历这个有序的特征值,计算他们的累计梯度值,从而得到最大的损失降低量,具体算法如下图所示:

(这个是不是传中的预排序??)
例:
对于每次扩展,我们还是要枚举所有可能的分割方案,如何高效地枚举所有的分割呢?我假设我们要枚举所有$x < a$这样的条件,对于某个特定的分割$a$我们要计算$a$左边和右边的导数和。
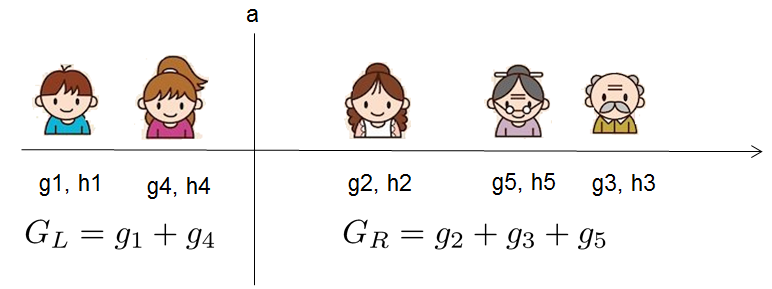
我们可以发现对于所有的a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和$G_L$和$G_R$。然后用上面的公式计算每个分割方案的分数就可以了。
近似分裂算法
传统的分裂方法虽然精确,但是十分耗时,而且一旦数据较多,非常占用内存,也不利于并行化。xbg提出了一种近似的算法,具体如下:

对于每个特征,只考察分位点,减少计算复杂度
- Global:学习每棵树前,提出候选切分点
- Local:每次分裂前,重新提出候选切分点
近似算法举例:三分位数
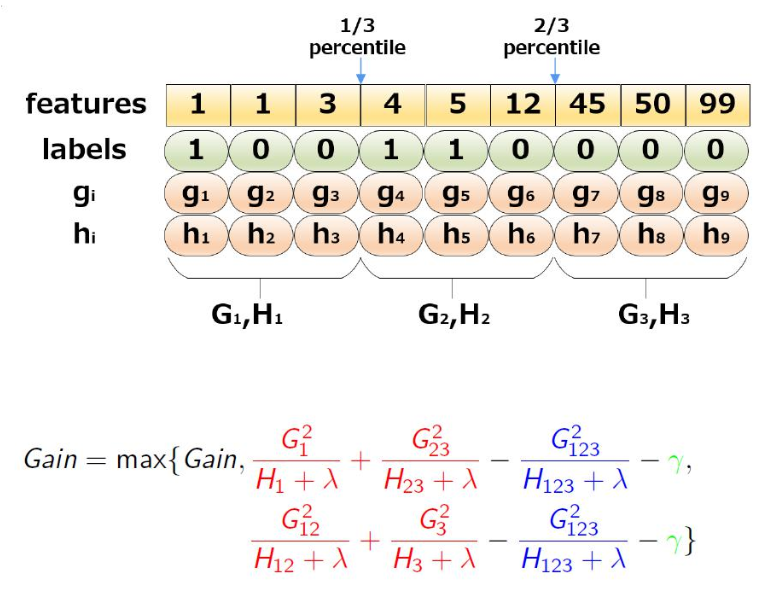
实际上XGBoost不是简单地按照样本个数进行分位,而是以二阶导数值$h_i$作为权重(WeightedQuantileSketch),比如:
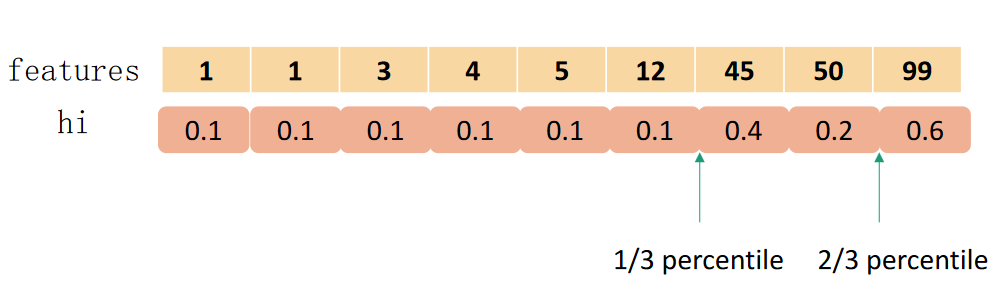
为什么用$h_i$加权?
把目标函数整理成以下形式,可以看出$h_i$有对loss加权的作用
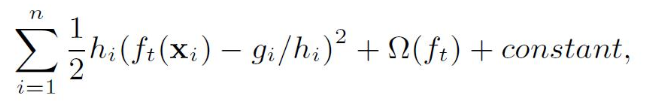
同时,xgb还有处理稀疏数据的算法:
真实数据中,稀疏是比较普遍的,造成稀疏的原因主要有以下几点:
- 存在缺失值
- 有很多0
- 人造特征,比如ont-hot编码

从该算法中,我们可以看出XGBoost缺失值处理方式是,对于某一个特征,假设所有缺失的样本属于右子树或者左子树,然后分别计算其损失减少量得分,最后取其最高值对应的分裂位和得分值。

其他
并行化,Column Block for Parallel Learning
XGBoost的特征重要性是如何得到的?某个特征的重要性(feature score),等于它被选中为树节点分裂特征的次数的和,比如特征A在第一次迭代中(即第一棵树)被选中了1次去分裂树节点,在第二次迭代被选中2次……那么最终特征A的feature score就是 1+2+….
含有缺失进行训练
dtrain = xgb.DMatrix(x_train, y_train, missing=np.nan)
xgboost相比传统gbdt有何不同?
作者:wepon
链接: https://www.zhihu.com/question/41354392/answer/98658997
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
参考资料
XGBoost: A Scalable Tree Boosting System
Introduction to Boosted Trees
xgboost原理
xgboost导读和实战.pdf
wepon_gbdt_ppt.pdf
xgboost github项目地址
Introduction to Boosted Trees_ppt_pdf
XGBoost浅入浅出