赛题回顾
京东金融提供8到11月的用户借款信息,订单购买信息,页面点击信息以及用户个人和贷款的初始额度信息;要求预测12月每个用户的贷款信息。评价方式采用RMSE函数:
$$RMSE = \sqrt {\frac{1}{n}\sum\nolimits_{i = 1}^n {{{({y_i} - {{\hat y}_i})}^2}} } $$其中yi真实值,y_hati为预测值,n为用户总数。
项目代码 github
数据下载,百度网盘 密码:2lk3
---- 20171219更新 ----
浪教授
- 以30天划分训练集,按30天为周期对齐;
- 滑动窗口特征,等差 每 7 天 10 天 等;
- 让预测月份的均值等于前几个月的均值(比赛前期);
- 强特征:激活日期、loan time、可贷款金额、 pid param组合前20个 one-hot
- 模型融合,加权平均
第17名代码
https://github.com/klyan/JDD_Loan_Forecasting
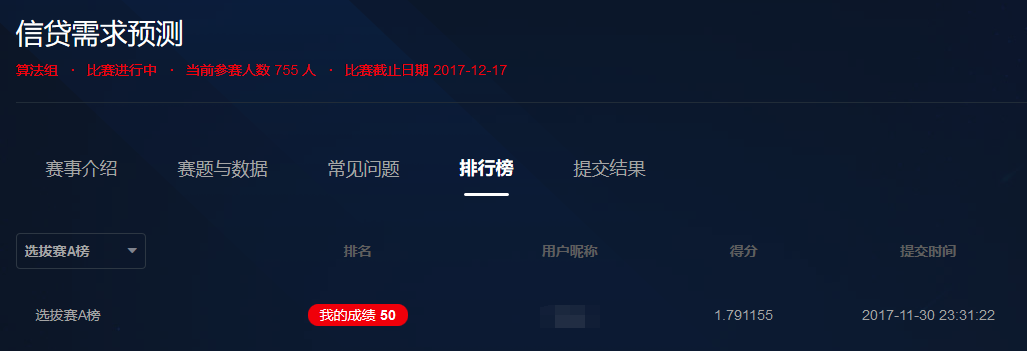
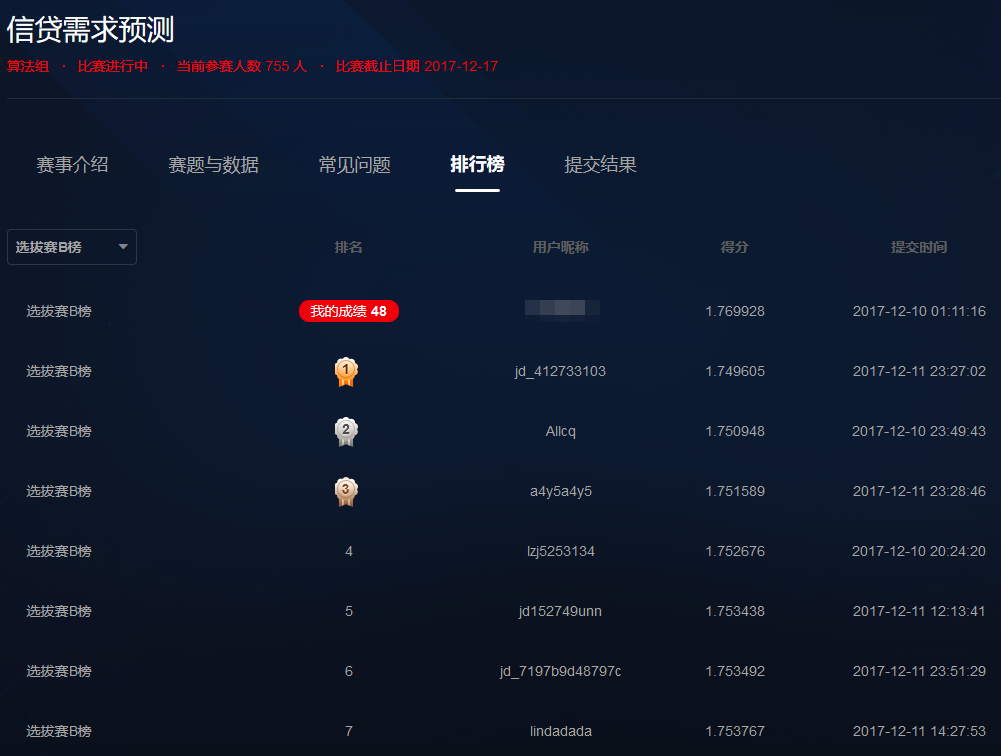
比赛结果
A榜50,B榜48
解决方案
- 数据分析
- 区间划分
- 特征提取
- 模型分析
- 模型调参
- 模型融合
数据分析
在本次比赛中,数据分析比较少,仅仅是用 Jupyter Notebook 简单的画了几个图,没有针对数据情况进行特定的特征提取,基本上是想到什么特征就用什么特征,然后 总和、平均、最大、最小、方差 这几个来一套。这是本次比赛中不足的地方。
赛题中对金额字段进行了加密,但是在竞赛群里,立刻就有大佬给出了加密($y = {\log _5}(x + 1)$)和脱敏($y = {5^x} + 1$)方法,我们直接使用该方法,效果提升非常明显。
区间划分
采用传统的划窗法对数据划分,注意:在划分数据时,一定不能出现数据穿越,即 训练的数据集中用到预测的数据 (如:要预测11月的贷款数据,则在训练数据中不能包含11月的数据信息) 否则会造成线下CV(交叉验证)效果非常好,但是线上糟糕。
本次比赛的划分方式我们尝试了两种方案:
- 方案一:
| 0 | 特征区间(feature) | 预测区间(llabel) |
|---|---|---|
| 训练集 | 2016-08-03到2016-10-31 | 2016-11-01到2016-11-30 |
| 测试集 | 2016-08-03到2016-11-30 | 2016-12-01到2016-12-31 |
- 方案二:
将测试集中的8到11月改成9到11月,即
| 0 | 特征区间(feature) | 预测区间(llabel) |
|---|---|---|
| 训练集 | 2016-08-03到2016-10-31 | 2016-11-01到2016-11-30 |
| 测试集 | 2016-09-01到2016-11-30 | 2016-12-01到2016-12-31 |
在实际测试中我们发现,本次比赛,在相同的特征提取方式下,方案一的结果优于方案二,因此采用方案一。
特征提取
这就比较多了。。。。
参数说明:
start_month 划分区间的起始月份
end_month 划分区间的结束月份
NUM 结束月份 - 起始月份 + 1,即 期间经过了NUM个月
user用户信息表
| 特征名 | 特征含义 |
|---|---|
| delta_time | 结束时间 - 激活时间 (天) |
| start_delta_time | 起始时间 - 激活时间 (天) |
| age,sex,limit | 年龄,性别,初始额度 one-hot编码 |
click点击信息表
这个表貌似没什么用,也不知道这里面具体参数是什么含义,所以直接one-hot编码
| 特征名 | 特征含义 |
|---|---|
| uid,param | 点击页面,点击参数 one-hot编码 |
loan贷款信息表
| 特征名 | 特征含义 |
|---|---|
| remain_days | 到下个月的天数 (平均、方差、最大、最小) datetime(2016, end_month+ 1, 1) - parse(x) |
| pass_days | 开始月的天数过去的天数 (平均、方差、最大、最小) parse(x) - dt.datetime(2016, start_month, 1) |
| over | 计划时间是否超出时间 |
| average_loan | 平均每月贷款 |
| loan_month | 区间内贷款额(最大、最小、方差) |
| average_pay | 每月月供(平均、最小、最大) |
| remain_loan | 历史贷款总额 |
| remain_pay | 累计月供 |
| current_loan_sum | 当月月供(总和、最大、最小、平均、方差) |
| current_pay | 当月贷款总额(总和、最大、最小、平均、方差) |
| pay_each | 每一次月供(最大、最小、平均) |
| loan_each | 每一贷款(最大、最小、平均) |
| average_plannum | 平均贷款还款周期 |
order订单信息表
参数说明:
per_price:用户购买单价
price_sum:购买总和
discount_ratio:优惠率
| 特征名 | 特征含义 |
|---|---|
| price_sum_mean | 每次购物的平均价格 |
| num_order | 每月购买次数(最大、最小、平均、方差) |
| price_each | 每个用户每次消费(最大、最小、平均、方差) |
| price | 每个用户购物价格(最大、最小、平均、方差) |
| real_price | 每个用户购物折扣后总价(最大、最小、平均、方差) |
| average_discount | 平均折扣 |
| qty_each | 每个用户每次购买(最大、最小、平均、方差) |
| discount_price_ration | 历史折扣力度(平均、方差) |
| no_free_discount_ratio | 每月非免费平均总价格/每月非免费平均折扣后的总价/每月非免费平均折扣力度/每月非免费平均折扣(平均、方差) |
| current_real_price | 每个用户当月的购买物品总价格和(平均、方差) |
| current_price | 当月平均单价(平均、方差) |
| current_no_freeprice | 当月非免费平均单价(平均、方差) |
| current_discount | 当月每次平均折扣(平均、方差) |
| current_discount_ratio | 每次折扣力度(平均、方差) |
order_loan 订单-贷款交叉信息
| 特征名 | 特征含义 |
|---|---|
| loan_order_ratio | 贷款总额 / 购买总额 |
| diff_order_loan | 购买总额 - 贷款总额 |
user_order 用户-订单交叉信息
| 特征名 | 特征含义 |
|---|---|
| diff_loan | 贷款总额和初始的差 |
模型分析
一看题目,咋们就很明显的看出这是一个回归问题,那么我们就先选用回归的各种模型来尝试,比如 GBDT、XGB、LR、 Ridge。
随后,我们通过分析数据发现,有相当大的一部分用户没有发生贷款行为,那么是否可以尝试采用先分类再回归呢?分为用户是否会贷款,如果否,直接将贷款值设为0;如果是,那么再用回归模型对用户的贷款行为预测。但是实际情况是,我们的分类模型得到的CV结果准确率仅为85%,加上分类再回归,反而导致了总体评分下降。在做了简单的尝试之后,我们便放弃了这个方法,还是直接使用回归模型。
模型调参
在这里,我们安利一个非常棒的 自动 特征处理(归一化、放缩)、模型选择、调参、模型融合的工具 TPOT,它是用遗传算法跑的,所以运行速度非常非常慢。在本次比赛中,我们一百多维的特征,9W多行(用户),TPOT参数设置:迭代25次,种群规模40,跑完一次,得到模型结果需要1-2天的时间。
此外,我们主要尝试了XGB和GBDT模型,最终的结果是GBDT要优于XGB,参数如下:
GBDT:
1 | X_train, X_test, y_train, y_test = train_test_split(train_X, train_Y, test_size=0.2, random_state=1) |
XGB:
1 | {'max_depth': 5, 'eta': 0.05, 'silent': 1, 'eval_metric': 'rmse', 'max_leaf_nodes': 5} |
模型融合
在这次比赛中,我们采用了Stacking融合方法,理解不深,只是简单尝试了一下:
1 | gbdt = GradientBoostingRegressor(loss='ls', alpha=0.9, |
但是效果不咋滴。
由于我们用了TPOT这个调参工具,根据它生成的模型,貌似已经加上模型融合,所以我们在这一块没有放上太多的时间。
还有其他几个模型融合方法,比如:blending,加权平均。据师兄介绍,加权平均的融合方法有时候能取得一个非常不错的结果。根据阿里天池O2O比赛第一名的分享,他们就采用了加权的方法O2O-Coupon-Usage-Forecast。
总结
初次比赛,还不懂套路,拿到赛题和数据后,我们没有做数据分析,直接巴拉巴拉暴力提取特征,导致很多特征都没有什么实际用处。另外在数据清洗上也没有进行操作,直接选取了全部数据;在一些缺失值,异常值(比如购买金额,贷款金额为负值)操作上,直接进行填零。不知道是否因为这些原因导致结果比较差。另外,在比赛初期,我们新增特征时,对结果有较大提高,特别是一些强特征(GBDT特征重要性排序),但在比赛后期,新增特征后,对结果几乎没有提高,有时甚至下降了。在本次比赛中,没有找到什么骚操作,也没有发掘出某个神奇的东西,对结果有大幅提高。但是,TPOT是个不错的东西,在特征确定的情况下,通过该工具,对模型调整有着突出的效果,缺点是运行速度太慢。过段时间,看看各位大佬的分享,再好好总结总结。
参考资料
如何在 Kaggle 首战中进入前 10%
第一次参加Kaggle拿银总结
[天池竞赛系列]O2O优惠券使用预测复赛第三名思路
O2O第一名【诗人都藏在水底】代码 思路
O2O第十六名代码 思路