连续撸了一整个清明假期的挑战赛代码终于结束了。作为比赛的最后,做个小小的总结。
一些小感悟
- 写代码的时候,千万不要为了方便随意使用全局变量,使用全局变量后,代码的耦合度大大提高。
- 对于这类比赛,能对特定的case进行特定的编程或者调参,对结果会有一定提升(可能会被禁止)。
- 对于每一次提交,保存好当前的提交版本,使用git是一个不错的方案。
- 看不懂的代码最好不要随意复制,出了问题怎么改都不知道。
- 团队的互相协助,是在比赛中陷入僵局时的解药。
题目
求解思路
基本思路是最小费用流+遗传
在刚看到题目的时候,很容易发现这是一个最优化问题,而且属于NP-难问题。因此我第一个想法就是,采用遗传或者粒子群算法进行求解,目标函数根据题意很快就可以写出,我们使用费用函数即可,但是却不知道怎么个编码,对服务器编码 or 网络流编码 or both。
直到我找到了最小费用最大流算法,使用该算法,输入服务器节点,即可计算出从服务器到满足各个消费节点需求的最小费用网络流路径。这样,结合第一个思路,算法的整体框架就很明确了。我们先通过遗传算法,产生一堆服务器节点,然后将这些服务器节点输入到最小费用流算法中,得出各条路径,通过路径和服务器信息我们既可以得出该方案下的网络费用,将费用作为遗传算法的适应度函数,再使用遗传算法中的变异、交叉、选择等操作,选出优秀的染色体,然后返回最小费用流算法,如此迭代循环。下面展示算法的流程图。
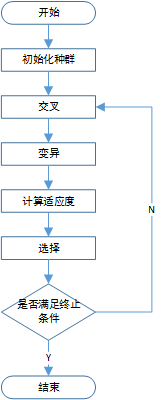
最大流、最小费用算法
算法的具体过程这里我就不展开了,放上比赛时,我们参考的一些文档与网页。
【PDF】网络流的应用
最小费用最大流
从入门到精通: 最小费用流的“zkw算法”
SPFA算法
SPFA是一种单源最短路径算法。在这个题目中,我们使用了最小费用流算法,网络中存在负权边,大家熟知的Dijkstra算法便失去了用武之地。SPFA该上场了。
SPFA算法的详细步骤,看看下面这个链接就好了(⊙o⊙)SPFA 算法详解( 强大图解,不会都难!)
接下来我说说针对赛题的改进策略。
首先,SPFA算法本身有两种改进策略:SLF 和 LLL
SLF:Small Label First 策略,设要加入的节点是j,队首元素为i,若dist(j) < dist(i),则将j插入队首,否则插入队尾。
LLL:Large Label Last 策略,设队首元素为i,队列中所有dist值的平均值为x,若dist(i)>x则将i插入到队尾,查找下一元素,直到找到某一i使得dist(i) <= x,则将i出对进行松弛操作。
SLF 可使速度提高 15 ~ 20%;SLF + LLL 可提高约 50%。
其次,我们在最小费用流使用SPFA算法时,我们只需要知道是否存在从S到T的路径,而不必需要他们之间的最短路径,因此,我们在求到了其中的一条路径时dist != null,即可返回,不必继续执行。
程序代码
比赛的代码我已经放到GitHub上,写的比较糟糕,没有优化,请各位大佬轻喷+_+